MongoDB Sharding(샤딩)
샤딩(Sharding)은 데이터를 여러 서버에 분산해서 저장하고 처리할 수 있도록 하는 기술이다.
복제 VS 샤딩
복제: 여러 서버가 서로의 데이터를 동기화하는 것
샤딩: 여러 서버를 분산하는 기술
MongoDB에서 복제와 샤딩의 목적을 혼동하는 경우가 많은데,
MongoDB의 복제는 고가용성(HA)을 위한 솔루션이며 샤딩은 분산처리를 위한 솔루션이다.
여기서 고가용성이란 서버와 네트워크, 프로그램 등의 정보 시스템이 상당히 오랜 기간 동안 지속적으로 정상 운영이 가능한 성질을 말하고, 분산처리는 데이터를 여러 서버에 분산해서 저장하고 처리할 수 있도록 하는 기술이다. 몽고DB에서는 고가용성을 위해서 중복된 데이터 셋을 준비하는 것이다.
그래서 MongoDB에서 고가용성과 대용량 분산처리를 하려면 복제와 샤딩 모두를 적용해야 한다.
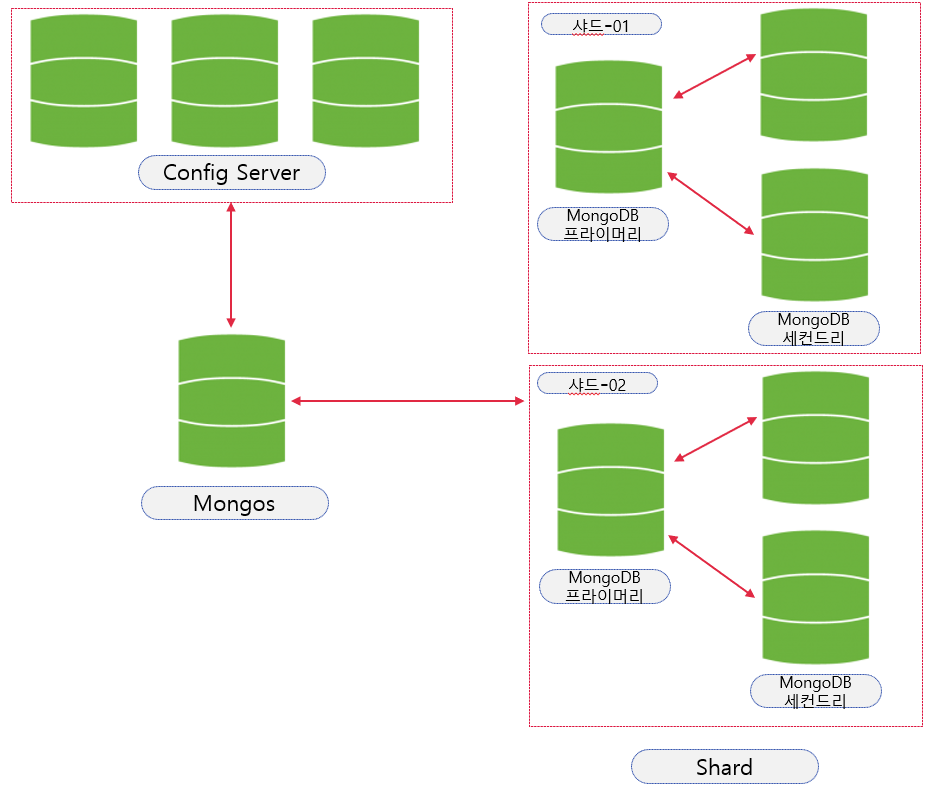
MongoDB에서 샤딩을 적용하려면 샤드 클러스(Sharded Cluster)를 구축해야 하는데, 이를 위해서는 파티션된 데이터의 범위와 샤드 위치 정보 등의 메타 정보를 저장하기 위한 컨피그 서버 (Config Server)가 필요하다. 그리고 응용 프로그램이 필요한 데이터를 조회하거나 저장하려면 "mongos"라고 불리는 라우터(Router) 서버가 필요하다.
그래서 MongoDB 샤드 클러스터의 3가지 컴포넌트는 다음과 같다
- 샤드 서버(Shard Server) : 샤드 데이터의 집합. 샤드는 Replica set이 될 수 있다.
- 컨피그 서버 (Config Server) : 컨피그 서버는 샤드 클러스터에서 사용자가 생성한 데이터베이스와 컬렉션들의 목록을 관리한다. (컨피그 서버도 샤딩이 될 수 있다)
- Mongos (라우터 서버) : 영구적인 데이터를 가지지 않으며, 사용자의 쿼리 요청을 어떤 사드로 전달할지 정하고, 각 샤드로부터 받은 쿼리 결과 데이터를 병합하여 사용자에게 돌려주는 역할을 한다.
참고도서: 대용량 데이터 처리를 위한 Real MongoDB/위키북스/이성욱