샤딩(Sharding)
샤딩이란 데이터를 여러 서버에 분산해서 저장하고 처리할 수 있는 기술을 말한다.
샤딩(Sharding) VS 복제 (Replication)
샤딩(Sharding)과 복제(Replication)는 둘 다 데이터베이스의 가용성과 확장성을 높이는 방법이다.
둘의 차이가 있다면 복제는 데이터베이스 서버의 데이터를 다른 서버들과 복사하여 저장하는 방식이다. 이렇게 복제된 데이터는 다른 서버에서 읽기 작업을 수행할 수 있으며, 원본 서버가 다운되었을때 백업 서버에서 데이터를 제공하여 가용성을 보장한다. 복제는 데이터의 가용성과 일관성을 보장하며,
읽기 작업을 분산시켜 성능을 향상시킬 수 있다. 그러나 쓰기 작업은 일반적으로 원본 서버에서 수행되며, 이는 복제된 서버간의 동기화 문제를 야기할 수도 있다.

샤딩은 데이터베이스를 작은 조각으로 분할하여 여러 서버에 분산시키는 방식이다. 이렇게 분할된 각각의 조각은 다른 서버에서 독립적으로 저장된다. 이러한 방식으로 데이터베이스를 분할함으로써, 데이터베이스의 규모가 커질수록 선형적으로 확장할 수 있습니다.
그러나 샤딩은 일부 데이터에 대한 조회 작업을 빠르게 수행할 수 있지만, 조인 작업등 데이터베이스 전체에 대한 작업에는 적합하지 않을 수 있습니다.
샤딩을 이해하기 전에 수평 파티셔닝에 대해서 이해할 필요가 있다. (Why? MongoDB에서 샤딩은 데이터베이스를 수평적으로 분할하여 여러 서버에 분산시키는 기술이기 때문)
수평 파티셔닝
수평 파티셔닝은 행(row) 기준으로 데이터를 나누는 방법입니다. 아래와 같이 행을 기준으로 수평 파티셔닝을 진행하여 각 서버에 분산 저장함으로써 시스템 성능을 향상 시킬 수 있습니다.
아래와 같이 수평 파티셔닝을 사용하면 데이터를 분산 저장함으로써 각 서버의 처리량을 균형있게 분산시킬 수 있습니다. 또한, 특정 사용자를 검색할 때는 해당 사용자가 저장된 서버에서만 검색하면 되므로 검색 속도가 빨라집니다.

샤딩의 종류
해시 샤딩 [Key(Hash) Based Sharding]
해시 샤딩은 데이터를 고루 분산시키는 방법 중 하나입니다. 데이터가 해시 함수에 의해 처리되어 일련의 해시값으로 변환됩니다. 그 다음 해시값이 지정된 샤드(분산 데이터베이스)에 분배됩니다.
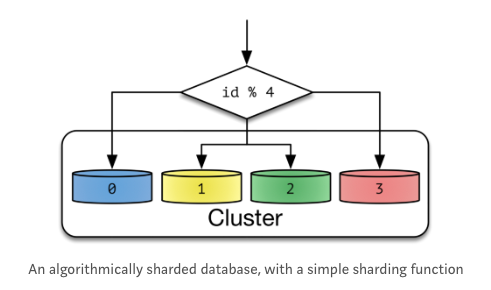
- Shard key를 Hash 함수에 넣어 나오는 값을 기준으로 분할한다
- Hash 결과가 균등하도록 Hash 함수를 정해야 한다
- ex) id % 4 -> 0 ~ 3 의 결과값으로 분산
장점
- 데이터가 균등하게 분산된다
- 샤드를 추가하거나 삭제하기 쉽다.
단점
- 샤드에 대한 부하가 불균형할 수 있다.
- 추가 증축을 위해 고비용의 데이터 재분배 작업을 해야한다 (기존 데이터까지 함께 ReSharding 필요)
- Hash 값으로 분산되기 때문에 공간에 대한 효율은 고려되지 않는다
범위 샤딩 [Range(Dynamic) Sharding]
범위 샤딩은 데이터를 범위 또는 구간으로 나누어 각 구간을 담당할 샤드를 선택하는 방식입니다. 데이터의 특성에 따라 구간을 나눌 수 있습니다. 예를 들어, 날짜 또는 지역별로 구간을 나눌 수 있습니다.
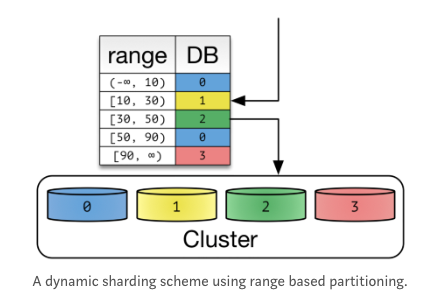
- 특정 feature의 범위 별로 분할한다
- 추가 증축하더라도 기존의 Shard Key 변경 없이 Locator에서 추가하면 된다
- 범위에 따라 데이터를 나누기에 데이터 분할 방법이 예측 할 수 있는 것이어야 한다
- ex) 인덱스, 생성 날짜, 우편 번호 등
장점
- 추가 증축에 데이터 재분배 작업이 필요 없다
- 데이터 검색 속도가 빠르다
단점
- 데이터가 골고루 분배되지 않기 때문에 노드간 트래픽 불균등 발생한다(샤드에 데이터 분배가 불균형)
- 샤드 추가 또는 삭제가 어려울 수 있다.
- 데이터 재분배 시 Locator의 Shard Key 테이블에도 동기화해야 한다 (관리포인트 증가)
- 성능상의 이슈로 캐싱을 하더라도 Locator에 의존해야만 한다 (결국 동기화 과정 필요)
지역성 샤딩 [Location-based Sharding]
지역성 샤딩은 지리적으로 가까운 데이터를 동일한 샤드에 저장하는 방식입니다. 지역성 샤딩은 대규모 지리 데이터를 처리하는데 적합합니다.

장점
- 지리적 데이터 검색이 빠르다
- 데이터 복제 및 복구가 쉽다
단점
- 데이터 분배가 불균형할 수 있습니다.
- 지역성이나 지리 정보가 없는 데이터에는 적합하지 않습니다.
'NoSQL > MongoDB' 카테고리의 다른 글
| MongoDB 인덱스 확인 (TTL 설정 확인) (0) | 2024.01.19 |
|---|---|
| MongoDB Sharding(샤딩) (0) | 2021.03.17 |
| MongoDB 정리 (0) | 2021.03.08 |
