
- Kafka 기본 개념 및 아키텍쳐
- 카프카의 주요 구성요소(Producer, Consumer, Broker, Topic, Partition)
- Producer: 메세지를 카프카로 전송하는 클라이언트. 데이터 생성자 역할
- Consumer: 카프카로부터 메세지를 읽어가는 클라이언트
- Broker: 카프카 인스턴스로, 메세지를 저장하고 전달하는 역할을 한다. 여러 브로커가 모여 클러스터를 이룬다.
- Topic: 메세지를 분류하는 논리적 단위. 데이터는 토픽에 기록된다.
- Partition: Topic은 여러 파티션으로 나눌 수 있다. 각 파티션은 독립적인 로그로, 메세지는 순서대로 저장된다. Partition을 나누면 병렬 처리가 가능하다.
- 카프카의 메세지 전달성 보장(At least once, At most once, Exactly once)
- At least once: 메세지가 한번 이상 전달된다. 중복 메세지가 발생할 수 있다.(기본설정)
- At most once: 메세지가 최대 한 번 전달된다. 메세지 손실 가능성이 있지만 중복은 없다.
- Exactly once: 메세지가 정확히 한번만 전달된다. 중복 및 손실 없이 안정적인 메세지 처리 보장(카프카 0.11부터 지원)
- Partion과 Replication의 차이점, 각각의 역할
- Partition: 데이터를 수평적으로 분산 저장하기 위해 토픽을 나눈것. 각 파티션은 독립적인 순서를 보장하며, 병렬 처리를 가능하게 한다.
- Replication: 데이터의 가용성과 내결함성을 보장하기 위해 Partition을 복제하는 것, Leader partition이 쓰기와 읽기를 담당하고, Follwer Partition이 복제본으로 유지된다.
- 카프카에서 Consumer Group의 동작, 이점
- Consumer Group 은 여러 Consumer가 같은 Group ID로 묶여, 서로 중복 없이 메세지를 병렬로 처리한다.
- 이점:
- 확장성: Partition 수에 따라 Consumer를 늘려 병렬 처리가 가능
- 내결함성: Consumer 중 하나가 실패해도 다른 Consumer가 처리를 이어받음
- 카프카에서 메세지 순서를 보장하려면?
- Patiotion단위로만 메세지 순서가 보장
- Key를 설정하면 Key를 가진 메세지는 같은 파티션으로 전송되어 순서가 유지
- 단일 파티션 사용시 순서보장은 쉬우나, 병목현상이 발생할 수 있다.
- 오프셋 관리 방식이란? 자동 커밋과 수동 커밋의 차이점
- 오프셋: Consumer가 마지막으로 읽은 메세지의 위치
- 자동커밋: 일정 주기로 자동으로 Offset을 커밋, 간편하지만 메세지 중복 또는 유실 위험이 있다.
- 수동커밋: 메시지 처리 완료 후 명시적으로 오프셋 커밋. 더 안전한 처리 방식
- 카프카에서 데이터 유실을 방지하기 위한 설정 방법
- acks = all: 모든 복제본에 메세지가 기록될 때까지 기다린 후 성공 응답
- replication.factor >= 2: 파티션 복제본 수를 늘려 장애 대비
- min.insync.replicas: 메세지가 성공 처리되기 위한 최소 복제본 수 지정.
- Producer 재시도 설정(retries): 전송 실패시 자동 재시도
- Retention Policy란? 설정방법
- Retetion Policy: 메세지를 카프카에 보관하는 기간이나 용량을 설정하는 정책
- 시간 기반: log.retetion.hours (기본 168시간, 7일)
- 용량 기반: log.retetion.bytes
- Retetion Policy: 메세지를 카프카에 보관하는 기간이나 용량을 설정하는 정책
- 고성능 처리를 위해 카프카의 어떤 설정을 최적화 할 수 있나?
- batch.size: 배치로 묶어서 보내는 메세지 크기 증가 → 네트워크 효율 향상
- linger.ms: 지정된 시간 동안 배치를 기다려 더 많은 메세지를 모은 후 전송.
- compression.type: 데이터 압축을 통해 네트워크 사용량 절감.
- num.partitions: Partition 수 증가로 병렬 처릴 강화
- 대용량 데이터 처리 시, 카프카 클러스터 확장(스케일링)은 어떻게 진행하나요?
- 수평확장: 새로운 브로커 추가 → 토픽의 파티션을 새 브로커에 분산
- 리밸렁싱: kafka-reassign-partitions.sh 스크립트를 통해 Partition 재배치.
- 필요시 Replication Factor 조정으로 데이터 복제 강화.
- 카프카에서 Backpressure 상황이 발생할 때 어떻게 대응하나?
- Backpressure: Consumer가 Producer의 메세지 속도를 따라가지 못할때 발생.
- 대응방법
- Consumer 성능 튜닝: 병렬처리, 배치크기 증가
- Partition 수 증가: Consumer Group 내 병렬성 확대
- Producer 조정: 전송 속도 제한, max.in.flight.requests.per.connection 설정.
- Backpressure: Consumer가 Producer의 메세지 속도를 따라가지 못할때 발생.
- Kafka Streams API와 KSQL?
- Kafka Streams API: Java 기반 애플리케이션에서 직접 스트림 처리 구현
- 장점: 강력한 프로그래밍 유연성, 복잡한 로직 구현 가능.
- 단점: 개발 복잡성, 유지보수 부담
- KSQL: SQL 기반 스트림 처리
- 장점:쉽고 직관적인 쿼리작성. 빠른배포
- 단점:복잡한 로직 처리에 한계
- Kafka Streams API: Java 기반 애플리케이션에서 직접 스트림 처리 구현
- Kafka에서 중복 메세지 처리나 PK 충돌 문제 해결
- Exactly Once Semantic(EOS) 활성화로 중복 방지
- DB에서는 Upsert 또는 ON CONFLICT 구문 활용
- 메세지 IDENPOTENCY 보장 로직 적용
- Kafka의 Exactly Once Semantics(EOS)란
- 메세지를 정확히 한 번 처리하는 기능
- Idempotent Producere와 Transactional Consumer 설정 필요
- 카프카와 RabbitMQ의 차이점
- 카프카: 대용량 스트리밍, 높은 처리량, 로그 저장에 강점
- RabbitMQ: 복잡한 라우팅, 즉각적인 메세지 전달, 낮은 지연시간에 적합
[KEYWORD]
브로커
파티션
메세지 유실
Consumer Group
PK 충돌
카프카의 주요 장점은 카프카가 다중 컨슈머를 지원한다는것. 다중 컨슈머 기능이란 여러개의 컨슈머 그룹이 서로간의 상호 간섭 없이 각자의 오프셋으로 각자의 순서에 맞게 메세지를 읽고 처리할 수 있는 것을 말한다.
이러한 방식은 컨슈머가 메세지를 읽으면 해당 메세지가 소비되어 다른 컨슈머에서 읽을 수 없게 되는 메세지 큐와는 다른 방식이다.
여기서 중요한 개념은 컨슈머 그룹인데, 카프카에서 동일한 group.id 속성을 공유하는 컨슈머들은 하나의 컨슈머 그룹으로 볼 수 있다. 그리고 토픽의 메세지를 읽을 때에는 컨슈머 그룹 각각 동일한 메세지를 개별적으로 읽어간다.

카프카에서 다중 컨슈머가 가능한 이유는 각각의 컨슈머 그룹들은 하나의 토픽 내의 메세지를 읽을 때 마다 메세지를 어디까지 읽었는지를 표시하는 오프셋을 개별적으로 관리하고 있기 때문이다. 그렇기 때문에 여러 컨슈머 그룹이 하나의 토픽에 붙어서 메세지를 읽더라도 개별적으로 동작할 수 있다.
그리고 카프카는 메세지를 디스크에 기록하고 저장한다. 이는 컨슈머가 메세지 읽기를 시도했다가 실패하더라도 메세지가 유실되지 않는 장점과 새로운 컨슈머 그룹이 토픽에 붙어서 메세지를 읽을때 과거에 기록된 메세지를 컨슈머가 읽을 수 있는 장점을 제공한다.
카프카 개발시 주의점
1. 메세지 순서 보장
도메인 로직중에는 논리적인 순서 보장이 중요한 것이 있다.
예를 들어 이커머스 서비스에서 고객이 특정한 상품을 주문하고, 이후에 해당 주문을 취소하는 이벤트가 발생했다고 가정해보자. 이 때 주문완료와 주문 취소의 메세지 처리 순서가 어긋나서 주문 취소 메세지를 먼저 처리하게 된다면,
우선 주문 취소 메세지에 담긴 주문 식별자는 존재하지 않을 것이기 때문에 주문 취소 과정에서는 오류가 발생하게 된다. 그리고 이후에는 주문취소와 관계없이 주문이 완료된 상태로 주문이 생성될 것이다.
이는 메세지의 처리 순서가 어긋나면 시스템이 의도와 다르게 동작하는 상황의 예시이다.
이러한 문제 상황이 발생하지 않으려면 메세지의 발행 순서에 맞게 시스템이 순차적으로 메세지를 읽고 로직을 처리할 수 있어야 한다. 그리고 이를 위해서 카프카는 토픽에 메세지를 발행할 때 메세지의 발행 순서에 맞게 시스팀이 순차적으로 메세지를 읽고 로직을 처리할 수 있어야 한다.
그리고 이를 위해서는 카프카의 토픽 메세지를 발행할 때 메세지의 키 값을 포함하여 메세지를 발행해야 한다.
카프카의 토픽은 여러 개의 파티션으로 구성되는데 메세지는 파티션에 추가되는 형태로만 기록되고 맨앞부터 제일 끝까지 순서대로 읽히게 된다. 즉, 카프카에서 메세지가 읽히는 순서는 토픽이 아닌 파티션별로 관리된다고 보면 된다.
그리고 프로듀서에서 카프카의 토픽에 메세지를 발행할 때에는 토픽의 여러 파티션중에서 어느 파티션에 기록할지 결정하는 로직이 있는데, 이것이 카프카의 파티셔너 로직이다.
파티셔너는 메세지에 키값이 없을때에는 라운드 로빈 방식으로 메세지를 분배하여 저장하고, 키가 있을때에는 해당 키 값의 해시를 구한 후에 그 값에 맞는 특정한 파티션에 메세지가 저장된다.

그렇기 때문에 메세지의 키값이 동일하면 항상 같은 파티션에 저장하게 된다.
이렇기 때문에 메세지의 순서가 중요한 도메인 로직에서 카프카에 메세지를 발행할 떄에는 여러 도메인 이벤트를 대표하는 도메인 식별자와 같은 값을 메세지의 키값으로 선언하여 메세지를 발행하는 것이 중요하다.
2.중복 메세지 처리
중복 메세지 이슈를 처리하려면 카프카가 관리하는 오프셋의 개념을 이해해야 한다. 카프카는 파티션의 각 레코드에 대한 위치를 숫자로 관리하는데, 이를 오프셋이라고 한다.
오프셋은 해당 파티션 내에서 레코드의 고유한 식별자 역할을 한다.
오프셋에서 컨슈머와 관련된 개념은 크게 2가지가 있다.
- Consumed Offset(Current Offset): 컨슈머가 메세지를 어디까지 읽었는가를 나타낸다. 해당 오프셋을 통해 컨슈머가 읽어야 할 다음의 메세지 위치를 식별할 수 있다. 해당 오프셋은 컨슈머가 poll()을 받을 때 마다 자동으로 업데이트가 된다. 해당 오프셋은 각각의 컨슈머가 관리한다.
- Committed Offset: 컨슈머가 메세지를 읽고 카프카에게 '여기까지의 오프셋을 처리했다'는 것을 알리는 Offset Commit을 통해 업데이트되는 오프셋이다. 컨슈머의 프로세스가 실패하고 다시 시작되면 컨슈머가 다시 메세지를 읽게 될 시작점이 되는 오프셋이기도 하다.
- Poll()메서드가 호출될 때마다 그룹의 컨슈머들은 파티션에서 아직 읽지 않은 메세지를 반환한다. 이 때 읽어들인 위치만큼 Consumed Offset이 업데이트 된다.
- 컨슈머에서는 읽어들인 메세지를 정상적으로 처리하고, 이후에 OffsetCommit을 실행하여 카프카에게 정상 처리된 메세지의 최종 위치를 알린다. 이때의 오프셋이 Committed Offset이다.
이러한 흐름은 컨슈머가 정상적으로 동작할때의 흐름이다. 그러나 만일 컨슈머에서 장애가 발생하거나 새로운 컨슈머가 컨슈머 그룹에 추가될 때에는 리밸런싱이 발생하고, 리밸런싱 이후에는 각 컨슈머에게 할당되는 파티션이 바뀔 수도 있게 된다.
이때 각각의 컨슈머는 각 파티션의 Committed Offset 부터 메세지를 읽어들이게 된다. 이 구간에서 중복 메세지 이슈가 발생할 수 있다.
- 컨슈머에서 읽어들인 메세지를 모두 정상 처리하고 이후 Offset Commit을 실행했다고 가정, 그리고 이때의 Committed Offset을 숫자 2라고 가정
- 이후 다시 poll() 메서드를 실행하여 일정한 수량만큼의 메세지를 읽고, 이때의 Consumed Offset을 숫자 11이라고 가정
- 이후 다시 Offset Commit을 실행하기 직전에 일련의 사유로 리밸런싱이 시작되었다고 가정. 그렇게 되면 리밸런싱이 완료된 이후에 해당 파티션의 소유권을 가진 컨슈머는 오프셋 11이후의 메세지를 읽는게 아니라, (과거에 이미 읽고 처리 완료한) Committed Offset2 이후의 메세지를 다시 읽게 된다. 이렇게 되면 컨슈머는 과거에 읽고 로직을 처리했을 수도 있는 메세지를 다시 처리할 가능성이 생기게 된다.
카프카 입장에서는 Offset Commit을 실행하기 전에 컨슈머가 읽어간 메세지가 정상적으로 처리 되었는지를 알 방법이 없기 때문에, 리밸런싱 이후에는 Committed Offset을 기반으로 메세지를 전달할 수 밖에 없다.
즉, 카프카를 활용한 비즈니스 구현시에는 Committed Offset 이후의 메세지구간에서 중복 메세지 이슈가 발생할 수 있다는 전제를 두고, 컨슈머가 이러한 상황을 스스로 해결해야함을 인지하는 것이 중요하다.
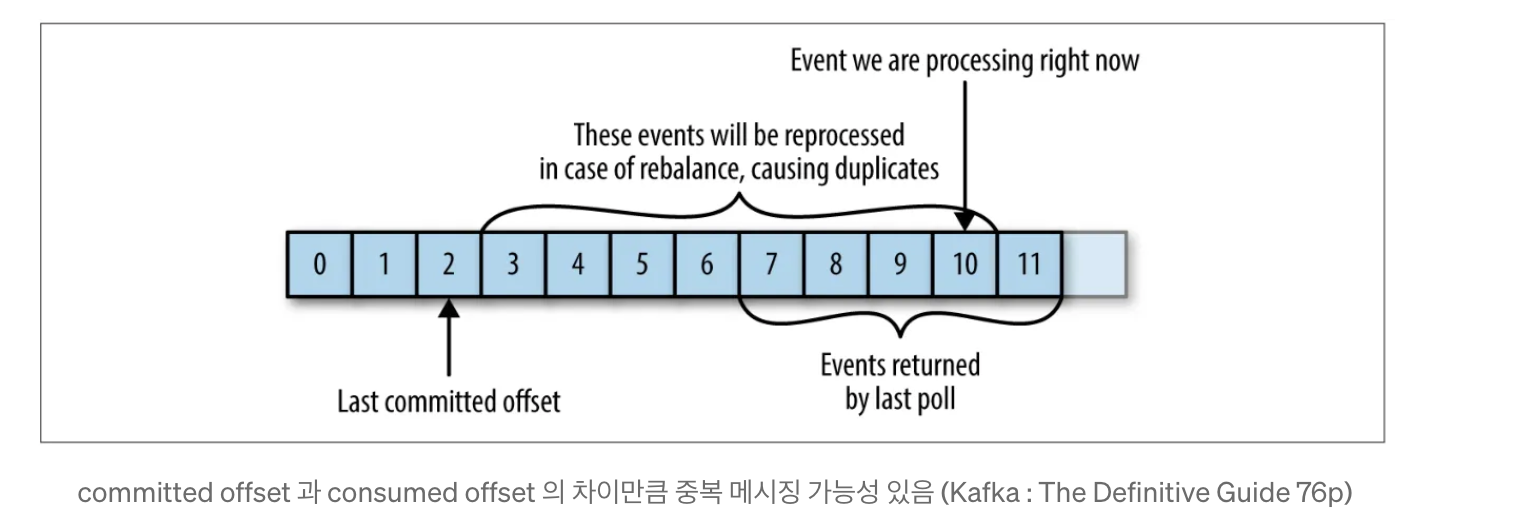
이와 같이 카프카를 통한 메세지 수신 과정에서는 메세지 중복이 발생할 수 있는데 애플리케이션 개발에서 중복 메세지를 처리할 수 있는 방안은 크게 2가지가 있다.
- 멱등한(idempotent) 메세지 처리 로직을 구현하기
- 중복 메세지를 걸러내는 로직 구현하기
1) 멱등한 메세지 처리 로직 구현하기
동일한 입력 값으로 로직을 반복적으로 실행해도 결과가 달라지지 않고 처음에 처리한 것과 동일한 결과를 가지는 성질을 멱등하다(idempotent) 고 말한다.
멱등성을 활용한다는 것은 카프카를 통한 메시지 수신은 중복으로 발생할 수 있지만, 설령 그렇더라도 처음에 실행한 것과 동일한 결과를 유지하게끔 로직을 구현하는 것을 말한다. 예를 들어 한번 취소한 주문을 다시 취소하는 것은 멱등성이 유지되는 로직이라고 볼 수 있다.
하지만 실제로 멱등성을 유지하면서 로직을 구현하는 것은 대부분 쉽지 않고, 비즈니스 의미상 멱등성이 불가능한 로직이 있을 수도 있다. 따라서 멱등성을 고려한 중복 메시징 처리는 제한적인 옵션이다.
2)중복 메세지를 걸러내는 로직 구현하기
1) 비즈니스 로직을 실행하는 것과 2) 읽고 처리한 메시지 정보를 insert 하는 것을 하나의 트랜잭션으로 묶어서 중복된 메시지가 실행되지 않도록 로직을 구현한다.
가령 PROCESSED_MESSAGE라는 테이블을 정의하고 메세지의 식별자를 해당 테이블의 유니크 인덱스로 걸어 놓는다면, 이미 처리된 메세지를 컨슈머가 다시 읽을 때에는 PROCESSED_MESSAGE에 insert를 하는 과정이 실패하고 전체 트랜잭션이 롤백되어 동일 메세지가 중복으로 실행되는 경우를 방지할 수 있게 된다.
'Kafka' 카테고리의 다른 글
| Kafka 컨슈머 장애 사례: 메시지 처리 시간 초과로 인한 CommitFailedException (0) | 2024.11.24 |
|---|---|
| Kafka에서 동시에 같은 메시지 처리 시 발생한 PK 중복 오류(feat. merge로 인한 장애대응) (0) | 2024.10.18 |
| 스프링 부트에서 Kafka 로그 관리하기: 불필요한 로그 숨기고 중요한 로그만 남기는 방법(feat. AppInfoParser) (1) | 2024.10.17 |
